AI视频生成 | AI 生成稳定视频工作流分享及效果展示
本文作者@周禹彤,未经同意,禁止转载搬运
AnimateDiff
AnimateDiff 使用稳定扩散模型将文字提示转化为视频,使用控制模块来影响稳定扩散模型。它通过各种视频短片进行训练。控制模块对图像生成过程进行调节,以生成一系列与其学习的视频片段相似的图像。与 ControlNet 一样,AnimateDiff 的控制模块可用于任何稳定扩散模型。目前仅支持 Stable Diffusion v1.5 模型。
在SD WebUI中的使用方法:https://www.bilibili.com/read/cv27508320/
在ComfyUI中的使用方法:https://www.bilibili.com/video/BV11m4y137AR/
01
提示词生成视频
方法
在提示词编写上,使用动词可以驱动AnimateDiff产生动画,例如walking、running、dancing等,类似wind会对头发和树叶产生影响。
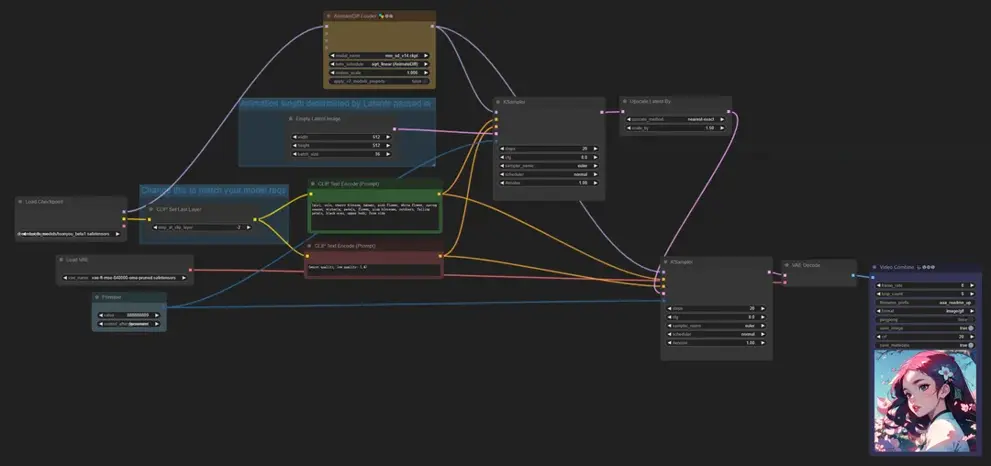
效果展示
对于单人角色比较简单的动作表现非常好,也适合制作风景类动画,对于多人物及一些复杂的动画比如格斗、跑步会略差一些。

02
图生视频
方法
输入第一帧和结束帧的图像制作动画
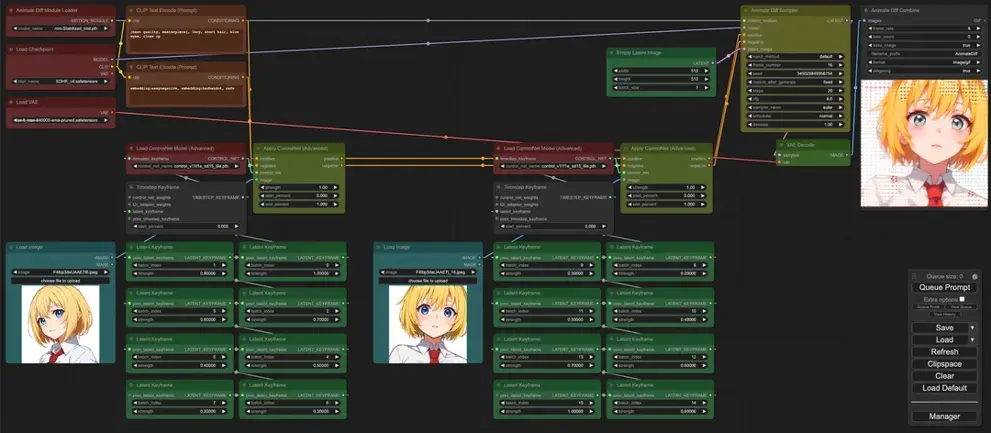
效果展示

03
提示词游历
方法
用Prompt Travel提示词游历语法,可以设置在不同的时间段使用不同的提示词产生不同的动画,适用于制作一些变形动画效果。
语法编写规则1:
帧数1:提示词1
帧数2:提示词2
以四季变换动画的提示词为例:
"0" :"spring day, cherryblossoms",
"25" :"summer day, vegetation",
"50" :"fall day, leaves blowing in the wind",
"75" :"winter, during a snowstorm, earmuffs"
语法编写规则2:
在提示词前后增加公共提示词
以模特换衣服动画的提示词为例:前部分控制模特容貌稳定,后部分让模特衣服变化
1 girl model,zend4y4,long hair,catwalking on the runway,stage lighting background,best
quality,masterpiece,hand painted textures,intricate details,realistic,
0: plaid_shirt,jeans,
16: plaid shirt,jeans,beret,
32: hooded track jacket,hot_pants,
48: white dress _shirt,buruma,
64: off-shoulder_dress,high_heel boots,
效果展示
能够生成时间较长的视频,且过渡效果丝滑。

04
ComfyUI+AnimateDiff+Controlnet 控制视频
AnimateDiff+Lineart控制
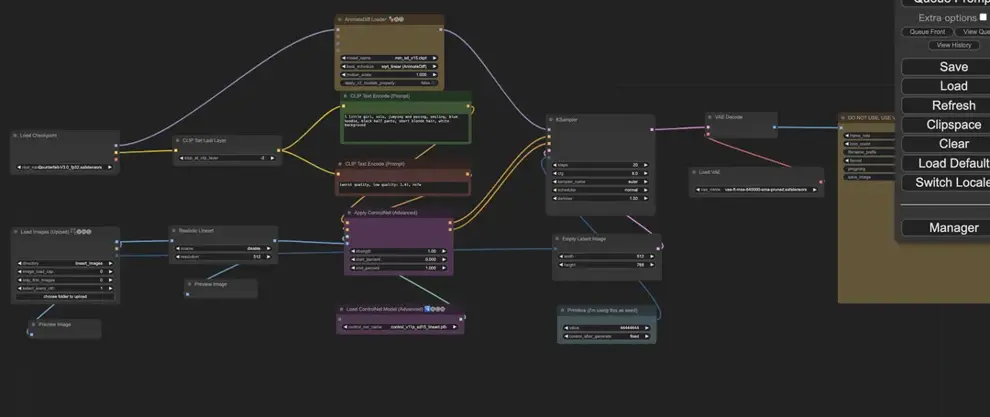
2D动画

Logo动画

AnimateDiff+Openpose+Depth控制
方法:选择一段质量较高的原视频,视频中的人物与背景易于区分,姿势可以用提示词清晰描述,使用艺术风格简洁的打模型和lora,最好使用 "提示词游历",随着视频的变化而改变提示词。提示词的细节对于让动画变得栩栩如生十分关键,比如加入:表情、眨眼等描述。
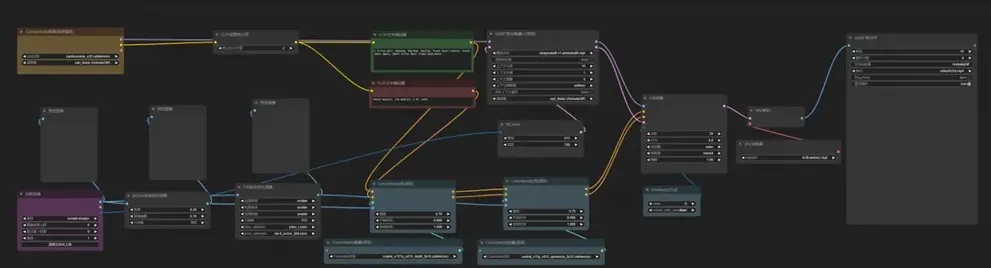

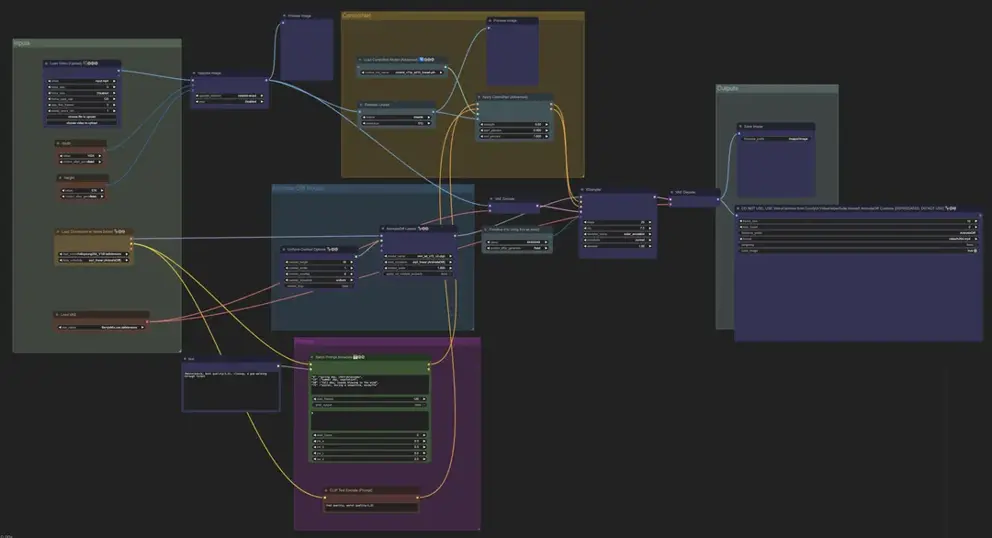
AnimateDiff+ControlNet+IPAdapter转风格重绘
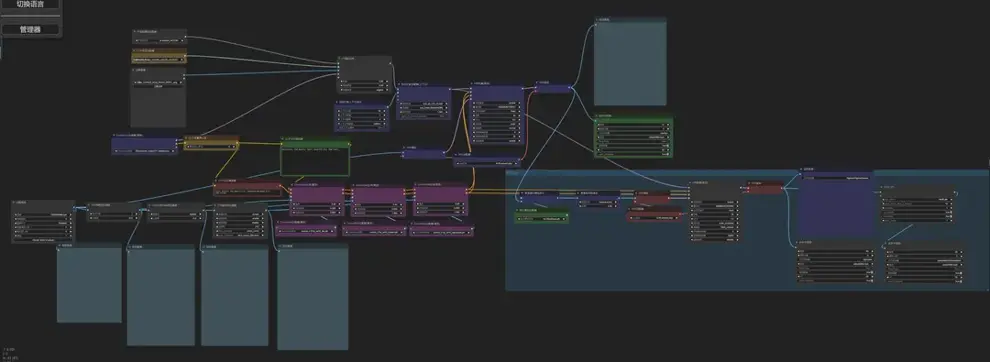

05
局部视频
方法
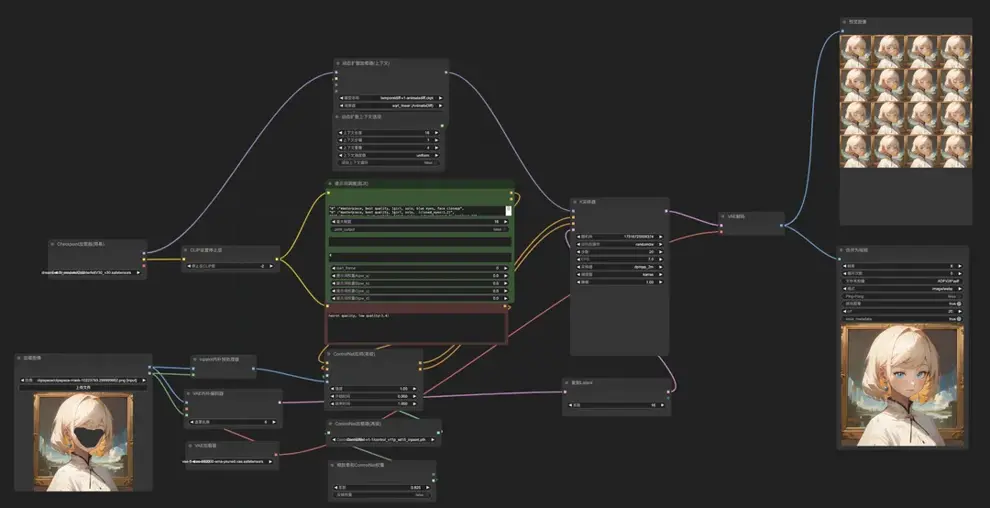
用提示词游历的方法可以让动画生成更准确,这里以眨眼动画为例:
"0" :"masterpiece, best quality, 1girl, solo, blue eyes, face closeup",
"6" :"masterpiece, best quality, 1girl, solo, face closeup, (closed_eyes:1.2)",
"11" :"masterpiece, best quality, 1girl, solo, face closeup, (closed_eyes:1.2),(smile:1.2)",
"15" :"masterpiece, best quality, 1girl, solo, blue eyes, face closeup"
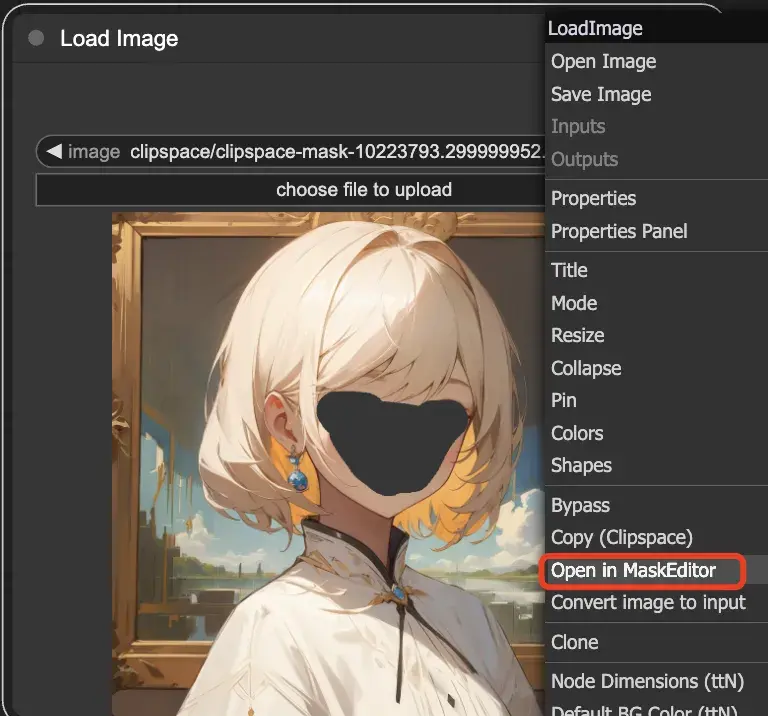
在Load Image节点中导入图片后,右键选择Open in MaskEditor即可涂抹重绘部分。
效果展示

Stable Video Diffusion
01
核心参数
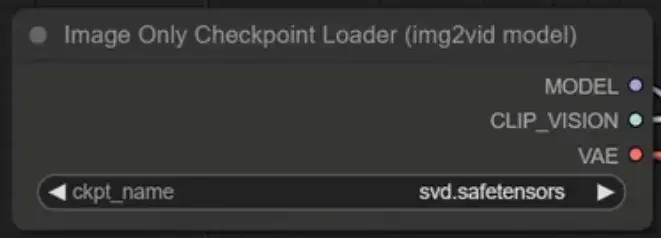
1. SVD模型下载(https://huggingface.co/stabilityai/stable-video-diffusion-img2vid/tree/main),模型通过此节点调用,svd.safetensors可在 576×1024 分辨率下生成 14 帧运动片段,svd_image_decoder.safetensors可在相同分辨率下生成 25 帧运动片段
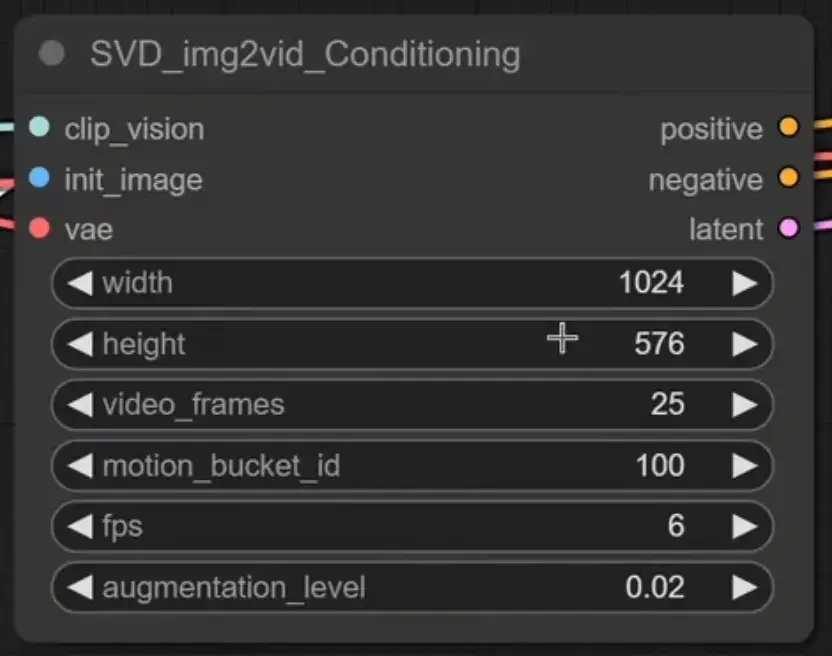
2. SVD img2vid Conditioning 节点
a.分辨率只可选择1024*576或576*1024,
b.video_frames: 要生成的视频帧数;
c.motion bucket id: 数字越大,视频中的运动越多;
d.fps: fps 越高,视频的断断续续就越少;
e.augmentation level: 添加到初始图像的噪声量,越高,视频看起来就越不像初始图像。增加它以获得更多运动。
02
使用方法
文字转视频
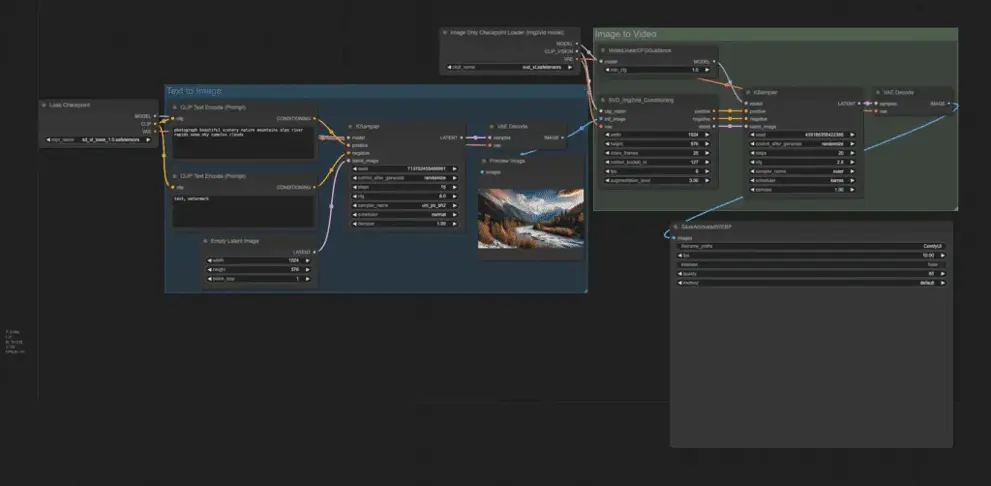

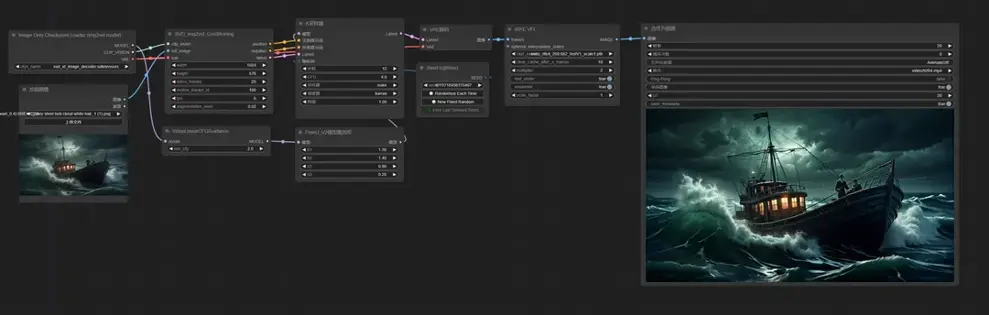
图片转视频

03
存在问题
时长很短,小于4s
分辨率限制
有时输出图像没有运动
模型无法通过文本进行控制
有时脸和身体的效果不友好
关于LitGate
大家好,我是LitGate,一个专注于AI创作的游戏社区。我们的新版官网已经上线✨你可以在里面找到各种AI创作的实操案例,以及已经沉淀的AI游戏创意demo,相信一定能让你大开眼界!
我们还有一个讨论群📣,如果你对AI创作感兴趣,或者有什么问题想要咨询,欢迎加入我们的讨论群,和大家一起交流学习!(PS:目前群内人数较多,为了有一个优质的讨论环境,请各位添加社区管理员企业微信账号邀请入群
更多精彩活动和功能筹备上线中,敬请期待~
关注我们,一起探索AI创作的无限可能吧!
新版官网地址:www.litgate.ai